I’ve been aware of this clause in TSQL for a long time, but I’ve never really used it. Mainly because I’ve rarely had the need to use windowing functions because I primarily work with XML and relational data that doesn’t need to be aggregated that often or have ranking applied to it. In the rare times that I could have used it, I have just stuck with what I knew probably because I never really truly understood the power of what it can do. Recently though on two consecutive days, this clause came to my aid and allowed to crunch out some really simple SQL super fast to achieve the tasks that I had. Its largely thanks to a short article that I read a few days prior that was talking about this clause and it was at that point onwards the penny dropped for me to what this is all about.
Over() – Day 1
On the first day, I was doing some basic one off aggregations from a table that had a whole bunch of numeric values that were being stored by customer per hour. What I wanted to do is to get the latest recorded value per customer based on the date. There was no consistency with the dates nor was it guaranteed that there will be records for each customer each hour. In the past for something this simple I would have jumped in with a helping of GROUP BY’s, sub queries MAX()/MIN() etc to get the data that I needed without an awful lot of thought to this throw away code. However this time, something in my head said hang on, there is a better way!
Imagine this very simplistic table + data:
--OVER() - Day 1
CREATE TABLE _tmp_SomeCustomerData
(
CustomerId VARCHAR(10),
StatsDate DATETIME,
SomeValue INT
)
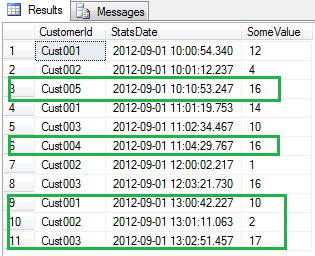
The records that I wanted in the final result are highlighted, namely the latest value based on the date/time for each customer. Using the OVER() clause makes such a query really easy to write and also importantly, very readable as well.
;WITH xCTE AS
(
SELECT ROW_NUMBER() OVER (PARTITION BY CustomerId ORDER BY StatsDate DESC) RowNo
, CustomerId
, StatsDate
, SomeValue
FROM _tmp_SomeCustomerData
)
SELECT CustomerId
, StatsDate
, SomeValue
FROM xCTE
WHERE RowNo = 1
I’ve done this using a CTE, but I could have quite easily put the CTE part into a sub query instead and to be honest, I think I did at the time!
This really simple query returns:
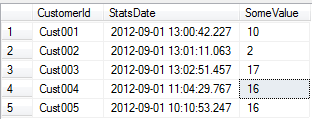
Really simple and nice. The ROW_NUMBER() function is giving each row in each partition a unique incrementing number starting from 1. Each customer is one partition and the rows in each partition are ordered by the date desc, as defined by the OVER() clause. So for each customer, the newest record is always given a ROW_NUMBER() of 1 and this is all we need to filter for to get the latest record for each customer.
Over() – Day 2
On the next day, I was looking at some data corruption and in one of the tables in one of my production databases. Imagine a column, not an identity column though, that is an incrementing number which starts at 1 for each customer in that table. However, for whatever reason, the incrementing number had gaps in the sequences for some of the customers and this was causing the application some problems. (it is a really, really old application so lets not go there!). Imagine this much reduced table schema
CREATE TABLE _tmp_SomeCustomerData
(
Id INT IDENTITY(1,1),
CustomerId VARCHAR(10),
NoteNumber INT
)
which contains the following data:
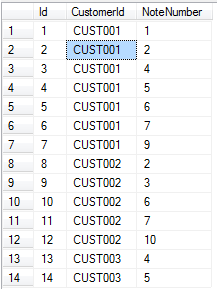
You can see lots of missing numbers from the sequences in the NoteNumber column. I was quite lucky that I could safely make the assumption that the NoteNumber will increase uniformly based on the Id column and that the first number for each customer will always be 1. In this scenario it is not possible to create record that had a NoteNumber earlier that one already stored for that customer. So I had to come up with a quick update query that would re-sync the numbers so that they were all sequential based on the customer. Again the OVER() clause with the ROW_NUMBER() function came to my aid here and allowed me to quickly create the following:
;WITH xCTE
AS
(
SELECT ROW_NUMBER() OVER (PARTITION BY CustomerId ORDER BY Id) AS 'NewNoteNumber'
, Id
FROM _tmp_SomeCustomerData
)
UPDATE _tmp_SomeCustomerData SET NoteNumber = NewNoteNumber
FROM xCTE
WHERE xCTE.Id = _tmp_SomeCustomerData.Id
Because all I needed was a list of sequential numbers partitioned by the customer ordered by the identity column Id, I am able to use the OVER() clause as a neat solution. The update query just joins the CTE on the Id column and updates the existing NoteNumber with the new sequential number generated by the CTE. The table of data after the update query now looks like this:
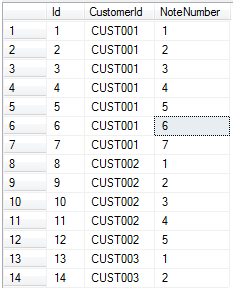
Don’t get me wrong, these are both really simplistic examples and usages for the clause and sure in both examples, it wouldn’t have been too much pain to crank out something similar that doesn’t use the OVER() clause. However, for me, the code is more readable and a lot easier to visualise in my head what what the query is doing.
For more information on this clause and how to use it on ranking or aggregate functions then this is probably a good starting point
Enjoy!